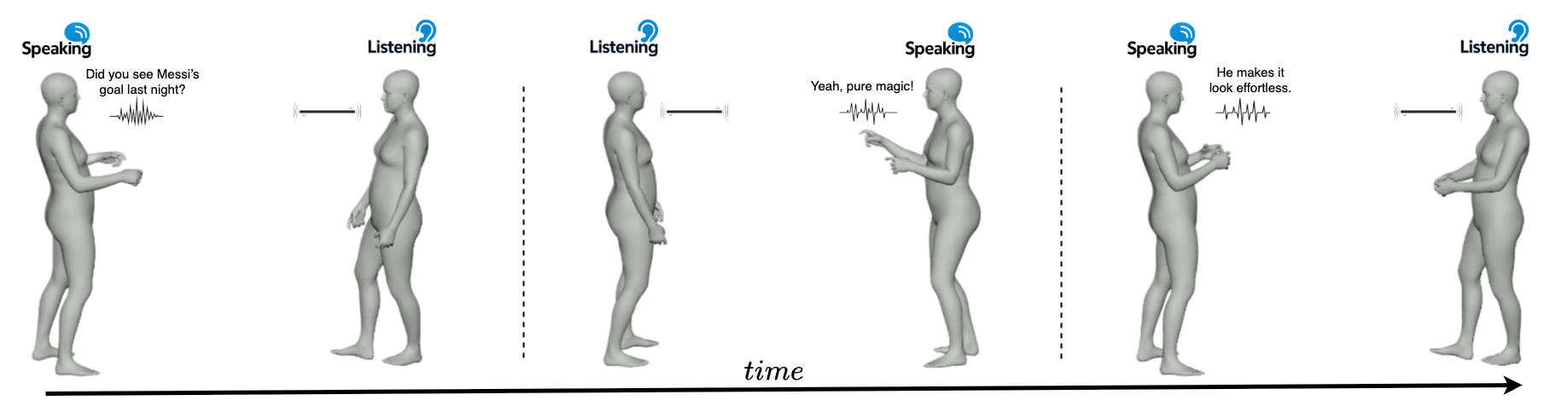
In this work we extend speaker-centric audio-driven gesture synthesis toward a unified conversational model that jointly captures both speaking and listening behaviors.
Existing speaker-centric models effectively generate gestures aligned with speech but overlook the bidirectional dynamics that characterize natural dialogue. To address this limitation, we propose the Conversational Gesture Model (CGM), a cross-attention-based model capable of synthesizing gestures conditioned on interlocutor conversational cues such as gestures, tone, and textual semantics. By leveraging cross-attention mechanisms, CGM fuses interlocutor audio and text features with character gesture encodings, enabling a single system to seamlessly alternate between speaking and listening roles of the same character.
Experiments demonstrate that this approach preserves the quality of speaker-driven gestures while significantly improving the realism, coherence, and responsiveness of full conversational interactions.
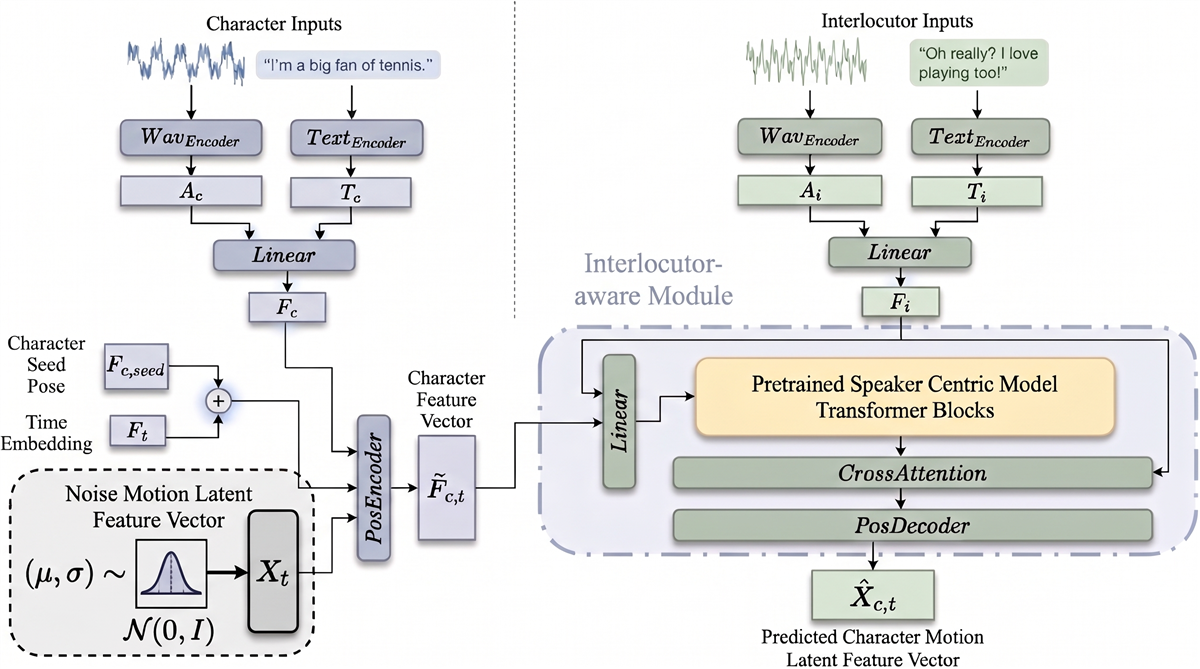
CGM augments a pretrained speaker-centric diffusion transformer with an interlocutor-aware cross-attention pathway. Character audio, text, seed pose, and noisy motion latents form the Character stream, while Interlocutor audio and text provide conversational context. The model fuses these signals to predict Character motion, enabling a single system to generate both speaking gestures and responsive listening behavior across role shifts.
To assess how CGM handles natural conversational dynamics, we evaluate it on full dyadic interactions where the Character alternates between speaking and listening in response to the Interlocutor. This setting tests whether the model synthesizes co-articulated behaviors and smooth transitions between conversational roles. The evaluation uses 7,320 Talking With Hands frames, approximately 4.1 minutes, spanning four dyadic conversations between paired participants.
| Method | ID 1 (Wayne) | ID 2 (Scott) | ID 6 (Carla) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| FGD ↓ | BC × 10−1 ↑ | Diversity ↑ | FGD ↓ | BC × 10−1 ↑ | Diversity ↑ | FGD ↓ | BC × 10−1 ↑ | Diversity ↑ | |
| GT | 0.000 | 7.855 | 9.578 | 0.000 | 6.696 | 9.578 | 0.000 | 6.966 | 9.578 |
| 3 Random Listener | 3.247 | 7.188 | 7.274 | 3.247 | 7.188 | 7.274 | 3.247 | 4.988 | 7.274 |
| SynTalker | 2.327 | 8.149 | 5.777 | 1.453 | 8.314 | 9.162 | 1.099 | 7.546 | 5.937 |
| DiffuseStyleGesture+ | 0.919 | 7.441 | 7.738 | 0.919 | 7.441 | 7.738 | 0.919 | 5.923 | 7.738 |
| Audio2Photoreal | 0.902 | 7.638 | 7.613 | 0.902 | 7.638 | 7.613 | 0.902 | 7.638 | 7.613 |
| Ours w/o Motion Encoding/Decoding | 0.731 | 7.584 | 6.412 | 1.102 | 7.903 | 7.221 | 0.682 | 6.944 | 6.938 |
| Ours w/o Listening-Aware Loss | 0.497 | 7.581 | 8.412 | 0.836 | 7.901 | 10.602 | 0.381 | 7.134 | 8.236 |
| Ours w/o Interlocutor-aware Module | 0.594 | 7.642 | 8.436 | 0.873 | 7.981 | 9.421 | 0.428 | 6.917 | 8.201 |
| Ours (CGM, Interlocutor-Aware) | 0.462 | 8.210 | 8.085 | 0.782 | 8.537 | 10.155 | 0.339 | 7.782 | 7.889 |
We investigate whether CGM can generate Character-specific listening gestures by leveraging pretrained speaker representations. For three Character IDs, we compare generated listening segments against ground-truth listening motion and speaking segments from each identity. Lower FID against ground-truth listening and the same Character's speaking style indicates stronger personalization, while higher distance from other Characters indicates clearer identity differentiation. The listening-focused Talking With Hands evaluation contains 2,702 frames, approximately 1.5 minutes.
| Generated Listening | GT Listening (FID) | ID 1 Speaking (FID) | ID 2 Speaking (FID) | ID 6 Speaking (FID) |
|---|---|---|---|---|
| ID 1 | 51.99 | 20.61 | 308.36 | 180.87 |
| ID 2 | 181.87 | 299.54 | 48.60 | 242.44 |
| ID 6 | 29.71 | 191.76 | 264.75 | 16.13 |
To evaluate rhythmic alignment during listening, we compare Character head motion against the Interlocutor audio. Generated head motion synchronizes more strongly with the true Interlocutor audio than with random audio offsets, approaching the ground-truth alignment reference.
| Head Alignment Setting ↑ | ID 1 | ID 2 | ID 6 | Audio2Photoreal |
|---|---|---|---|---|
| GT vs. Interlocutor Audio | 0.850 | 0.850 | 0.850 | 0.850 |
| Generated vs. Interlocutor Audio | 0.744 | 0.750 | 0.813 | 0.749 |
| Generated vs. Random Audio | 0.674 | 0.647 | 0.691 | 0.711 |
We verify that the interlocutor-aware modules do not degrade the original Character motion generation quality. This evaluation uses the BEATX test set, consisting of 29,310 frames, approximately 16.3 minutes of speech, collected from 15 different sessions.
| Method | ID 1 (Wayne) | ID 2 (Scott) | ID 6 (Carla) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| FGD ↓ | BC × 10−1 ↑ | Diversity ↑ | FGD ↓ | BC × 10−1 ↑ | Diversity ↑ | FGD ↓ | BC × 10−1 ↑ | Diversity ↑ | |
| GT | 0.000 | 6.580 | 14.141 | 0.000 | 8.440 | 12.638 | 0.000 | 1.907 | 8.637 |
| SynTalker | 0.258 | 6.781 | 5.466 | 0.307 | 8.364 | 10.697 | 0.481 | 3.565 | 7.794 |
| Ours w/o Motion Encoding/Decoding | 0.356 | 7.520 | 3.221 | 0.527 | 7.137 | 4.266 | 0.768 | 5.445 | 5.832 |
| Ours w/o Listening-Aware Loss | 0.213 | 6.402 | 7.914 | 0.417 | 8.063 | 12.601 | 0.589 | 5.911 | 8.674 |
| Ours w/o Interlocutor-aware Module | 0.241 | 6.612 | 6.882 | 0.352 | 8.201 | 11.146 | 0.512 | 4.982 | 8.031 |
| Ours (CGM, Interlocutor-Aware) | 0.190 | 6.796 | 6.101 | 0.484 | 8.794 | 14.074 | 0.621 | 6.774 | 9.286 |
In side-by-side comparisons, participants preferred CGM over DiffuseStyleGesture+ in the pooled setting, while CGM was statistically indistinguishable from ground truth. This suggests the model improves over the conversational baseline while approaching real motion quality in the tested clips.
| Condition | Ours (n) | Not Ours (n) | Prop. Ours | Binomial p |
|---|---|---|---|---|
| DiffuseStyleGesture+ pooled | 87 | 53 | 0.62 | .005 |
| Ground truth pooled | 36 | 34 | 0.51 | .905 |
@article{https://doi.org/10.1111/cgf.70412,
author = {Koren, T. and Rosenthal, A. and Friedman, D. and Shamir, A.},
title = {Conversational Gesture Model (CGM): Extending Speaker-Centric Audio-Driven Motion Generation to Full Conversation Gestures},
journal = {Computer Graphics Forum},
volume = {n/a},
number = {n/a},
pages = {e70412},
doi = {https://doi.org/10.1111/cgf.70412},
url = {https://onlinelibrary.wiley.com/doi/abs/10.1111/cgf.70412},
eprint = {https://onlinelibrary.wiley.com/doi/pdf/10.1111/cgf.70412}
}